


Cientistas de dados e empresas criam modelos de machine learning a todo momento para os mais diversos tipos de tarefas e especificidades, então é bem capaz de ao se deparar com a necessidade de ter que usar um modelo para classificação de textos ou geração de imagens, por exemplo, você já possa começar de um ponto de partida mais avançado ou até mesmo apenas consumir um que esteja 100% alinhado com o que você precisa.
Além dos artigos dos pesquisadores que contribuíram para a construção desses modelos, uma ótima fonte para encontrá-los é na plataforma Hugging Face. Ela conta com uma interface amigável e diversos filtros disponíveis, como por exemplo a atividade fim do modelo:
Para demonstrar a aplicabilidade da Hugging Face, vou utilizar um modelo de classificação de sentimentos para analisar comentários de compras do dataset da Olist. Esse conjunto de dados contém avaliações dos consumidores e o modelo será capaz de identificar automaticamente se o sentimento por trás dos comentários é positivo, neutro ou negativo.
Exemplo prático de classificação de sentimentos em comentários
Como o dataset que eu vou analisar possui comentários em português, eu irei usar o modelo pysentimiento/bertweet-pt-sentiment. Para conseguir utilizar ele é necessário que sejam instaladas as bibliotecas transformers e a PyTorch executando o seguinte comando no seu ambiente de desenvolvimento:
pip install transformers torch
Após importar as bibliotecas necessárias para as análises, a referência e download do modelo são feitos usando a classe pipeline da biblioteca transformers.
import numpy as np
import pandas as pd
from pathlib import Path
from pprint import pprint
from transformers import pipeline
modelo_sentimento = pipeline(
task="sentiment-analysis",
model="pysentimiento/bertweet-pt-sentiment"
)
Para testar se o modelo foi carregado corretamente, você pode passar um texto diretamente da célula do seu notebook para ver se não é exibida nenhuma mensagem de erro e como é o formato da resposta.
resposta_modelo = modelo_sentimento(
"gostei bastante do produto recebido",
top_k=None
)
pprint(resposta_modelo)

Aqui pudemos ver que além de trazer o sentimento do texto o algoritmo traz também o score de cada um deles, podendo ser bem útil ao lidar com casos mais ambíguos.
Agora, vamos carregar o dataset com as notas e comentários das compras feitas pelos clientes.
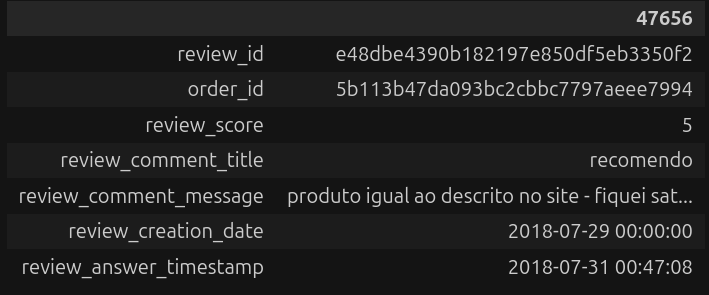
caminho_arquivo = "/home/henrique/Projetos/olist-brazilian-ecommerce-analysis/data/raw/olist_order_reviews_dataset.csv" avaliacoes = pd.read_csv(caminho_arquivo) avaliacoes.head(1).T
Como é possível ter informações úteis tanto no título quanto no corpo do texto do comentário, eu irei concatenar os dois e realizar alguns tratamentos para facilitar a análise de sentimento pelo modelo.
# Concatena o título do comentário com o seu conteúdo
avaliacoes["review_text"] = (
avaliacoes["review_comment_title"].fillna("")
+ " "
+ avaliacoes["review_comment_message"].fillna("")
)
# Converte para letras minúsculas
avaliacoes["review_text"] = avaliacoes["review_text"].str.lower()
# Remove caracteres especiais
avaliacoes["review_text"] = avaliacoes["review_text"].str.replace(
r"[^\w\s]", " ", regex=True
)
# Remove números
avaliacoes["review_text"] = avaliacoes["review_text"].str.replace(
r"\d+", "", regex=True
)
# Remove quebras de linhas
avaliacoes["review_text"] = avaliacoes["review_text"].str.replace(
r"\n", " ", regex=True
)
# Remove espaçamento múltiplo
avaliacoes["review_text"] = avaliacoes["review_text"].str.replace(
r"\s+", " ", regex=True
)
# Remove espaços como primeiro ou último caracteres
avaliacoes["review_text"] = avaliacoes["review_text"].str.strip()
# Substitui strings vazias por NaN
avaliacoes["review_text"] = avaliacoes["review_text"].replace("", np.nan)
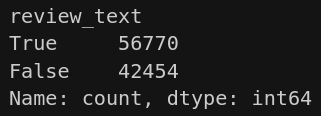
Com a execução desse código, a nova coluna criada já deve desconsiderar casos onde o comentário é um ponto ou apenas um espaço em branco, ficando aqueles que tenham pelo menos 1 palavra. Para ter uma dimensão da proporção de comentários nas avaliações, vamos contar os NaNs na coluna “review_text”.
avaliacoes["review_text"].isna().value_counts()
Agora, irei selecionar 1.000 comentários aleatórios da base e as três variáveis “review_id”, “review_score” e “review_text”.
amostra_comentarios = avaliacoes.loc[
avaliacoes["review_text"].notna(),
["review_id", "review_score", "review_text"]
].sample(1000).copy()
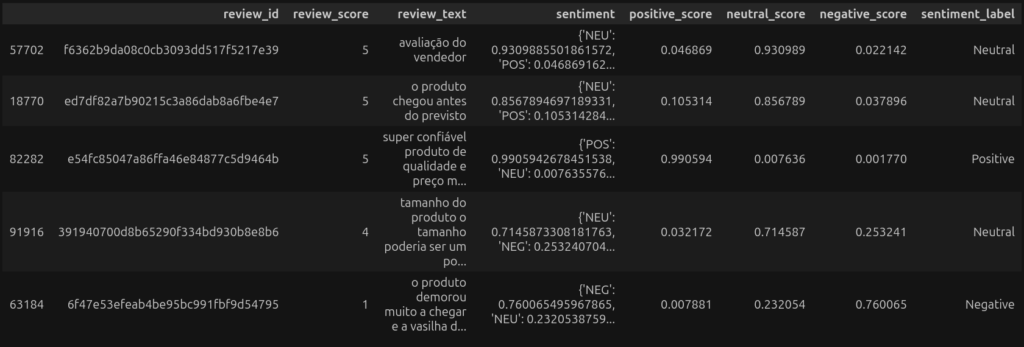
Além da lista de dicionários retornada pelo modelo, ao analisar uma linha com comentário eu também irei criar uma coluna para cada score dos três sentimentos e mais uma outra coluna que traz apenas o sentimento de maior pontuação.
# Cria uma coluna com o dicionário de sentimentos e seus respectivos scores
amostra_comentarios["sentiment"] = amostra_comentarios["review_text"].map(
lambda x: {
dictionary["label"]: dictionary["score"]
for dictionary in modelo_sentimento(x, top_k=None)
},
na_action="ignore",
)
# Separa o sentimento em diferentes colunas
amostra_comentarios["positive_score"] = amostra_comentarios[
"sentiment"
].map(lambda x: x["POS"] if isinstance(x, dict) else np.nan)
amostra_comentarios["neutral_score"] = amostra_comentarios["sentiment"].map(
lambda x: x["NEU"] if isinstance(x, dict) else np.nan
)
amostra_comentarios["negative_score"] = amostra_comentarios[
"sentiment"
].map(lambda x: x["NEG"] if isinstance(x, dict) else np.nan)
# Cria uma coluna com o sentimento de maior score para o comentário
sentiment_labels = {"POS": "Positive", "NEU": "Neutral", "NEG": "Negative"}
amostra_comentarios["sentiment_label"] = amostra_comentarios[
"sentiment"
].map(
lambda x: sentiment_labels.get(max(x, key=x.get))
if isinstance(x, dict)
else np.nan
)
amostra_comentarios.head()
Para analisar se a classificação de sentimento foi feita de forma adequada, irei selecionar aleatoriamente 5 comentários e notas de cada um, começando pelos positivos.
# Positivos
print(
amostra_comentarios
.loc[amostra_comentarios["sentiment_label"] == "Positive", ["review_score", "review_text", "positive_score"]]
.sample(5)
.to_markdown()
)

Vemos aqui que a classificação feita pelo modelo concorda tanto com o texto escrito quanto com a nota dada pelo cliente, sem grandes insights.
# Neutros
print(
amostra_comentarios
.loc[amostra_comentarios["sentiment_label"] == "Neutral", ["review_score", "review_text", "neutral_score"]]
.sample(5)
.to_markdown()
)

Nos comentários classificados como “neutros” podemos ver notas nos dois extremos. As notas máximas trazem dois comentários indicando que o produto foi entregue normalmente sem problemas enquanto o terceiro diz que o produto veio com defeito mas a loja responsável irá realizar a troca. Já nas notas mínimas, um deles o próprio cliente diz que o produto está no prazo de entrega mas ele avaliou com 1 estrela o pedido, enquanto no outro o cliente informa que a entrega foi feita parcialmente com a falta de um dos produtos.
# Negativos
print(
amostra_comentarios
.loc[amostra_comentarios["sentiment_label"] == "Negative", ["review_score", "review_text", "negative_score"]]
.sample(5)
.to_markdown()
)

Por fim, nos comentários classificados como “negativos” temos notas neutras e detratoras e comentários abordando os seguintes temas: produtos não entregues (ou entregue depois do prazo), produto diferente do divulgado no site e a cobrança de frete feita de forma individual para produtos repetidos.
Um outro uso para o modelo é tentar entender casos onde o sentimento é positivo mas a nota detratora ou sentimento é negativo mas a nota é promotora. Vamos agora pegar uma amostra de 5 comentários que estão em uma dessas duas situações.
# Notas divergentes do sentimento
print(
amostra_comentarios
.loc[
((amostra_comentarios["sentiment_label"] == "Positive") & (amostra_comentarios["review_score"].isin([1, 2])))
|
((amostra_comentarios["sentiment_label"] == "Negative") & (amostra_comentarios["review_score"].isin([4, 5]))),
["review_score", "review_text", "sentiment_label"],
]
.sample(5)
.to_markdown()
)

O segundo e terceiro comentários da amostra mostram que apesar do cliente elogiar a plataforma de compra e o produto recebido ainda assim ele deu uma nota baixa. Uma ação possível seria ignorar essas avaliações na composição das métricas das lojas que efetuaram essa venda, já que claramente não houve nenhum problema. O primeiro e último comentários trazem reclamações sobre preço e prazo do frete mas com notas boas, o que indica que o produto solicitado não era tão urgente para o último comentário enquanto o primeiro indica que provavelmente foi comprado um produto de baixo valor agregado e com um vendedor distante do comprador. Já o quarto comentário mostra o atraso de um dos produtos da compra mas com uma nota boa porque o outro produto chegou dias antes do prazo final.
Caso você já tenha contato com a linguagem de programação Python o uso dos modelos pré-treinados acaba sendo relativamente fácil com o uso da plataforma Hugging Face. Lembrando que cada modelo pode usar diferentes bibliotecas e podem ter formas diferentes de serem usados, sendo necessário sempre ver o código de exemplo disponibilizado na aba “Model card”.
Para dúvidas específicas de um modelo escolhido é possível abrir uma discussão no próprio link do modelo na aba “Community”, enquanto que para dúvidas mais genéricas o usuário ainda tem a opção de usar o fórum do Hugging Face para interagir com outras pessoas.
Deixe um comentário