

Com a crescente complexidade das análises e dos projetos de dados envolvendo diversos datasets diferentes, o versionamento dos dados usados (e gerados) se torna muito importante para se manter a reprodutibilidade e a transparência dos resultados. O Data Version Control (DVC) surge como uma boa opção de ferramenta para gerenciar e versionar datasets, permitindo que analistas e cientistas de dados acompanhem as mudanças nos dados de maneira similar ao versionamento do código. Além disso, o DVC se integra perfeitamente com sistemas de controle de versão como o Git e em editores de códigos como o VS Code.
A seguir serão mostrados o processo de instalação dele e um exemplo de uso prático.
Como instalar o DVC no meu computador?
O DVC é escrito na linguagem Python e para evitar que haja conflito com outras bibliotecas nativas do seu sistema é recomendado instalar ele usando o pipx.
O pipx permite que aplicações Python sejam executadas em ambientes isolados e sua instalação é feita com os comandos:
- No Ubuntu;
sudo apt update sudo apt install pipx pipx ensurepath
- No Windows.
python3 -m pip install --user pipx
Com isso, o DVC pode agora ser instalado usando o pipx executando o comando no terminal:
pipx install dvc[all]
Obs: o trecho “[all]” permite que sejam configurados todos os armazenamentos remotos compatíveis com o DVC, tais como Amazon S3, Azure Blob Storage, Google Cloud, dentre outros.
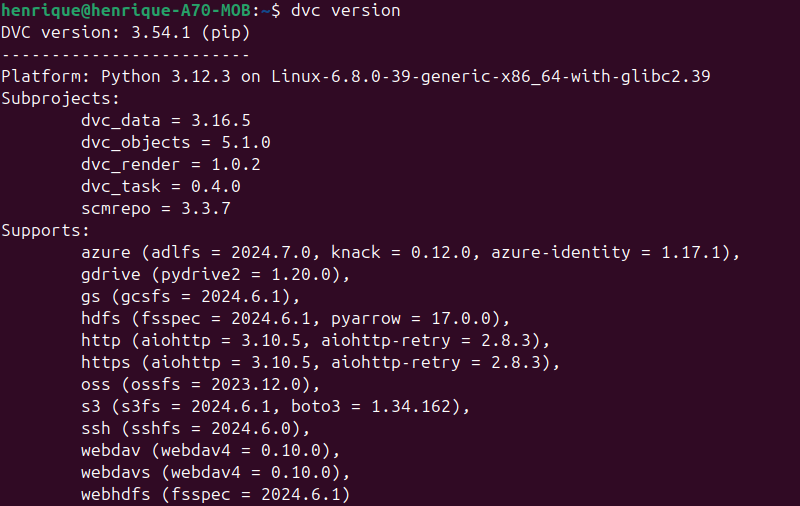
Para ter certeza que o DVC foi instalado, execute o comando dvc version e verifique a sua versão e as dependências instaladas.
Instalando adicionais para uso do Google Cloud como repositório remoto
Como vou usar o Google Cloud para salvar as versões dos dados do meu projeto de exemplo, é necessário instalar alguns pacotes adicionais. que são pré-requisito para o Google Cloud CLI:
sudo apt-get update sudo apt-get install apt-transport-https ca-certificates gnupg curl
Para seguir com a instalação do CLI, basta executar os seguintes comandos na sequência para:
- Importar a chave pública do Google Cloud;
curl https://packages.cloud.google.com/apt/doc/apt-key.gpg | sudo gpg --dearmor -o /usr/share/keyrings/cloud.google.gpg
- Adicionar URL do gcloud CLI como fonte de instalação de pacotes;
echo "deb [signed-by=/usr/share/keyrings/cloud.google.gpg] https://packages.cloud.google.com/apt cloud-sdk main" | sudo tee -a /etc/apt/sources.list.d/google-cloud-sdk.list
- Instalar o gcloud CLI.
sudo apt-get update && sudo apt-get install google-cloud-cli
Com o CLI instalado, você deve executar gcloud init para escolher o login e projeto da sua conta Google Cloud.
Lembrando que essas instalações adicionais foram necessárias porque escolhi o Google Cloud Storage como armazenamento remoto para os meus arquivos. Caso deseje usar outra opção, é possível consultar a compatibilidade com outros serviços em DVC Remote Storage.
Como configurar e usar o DVC para versionar os meus dados?
Para exemplificar aqui, irei mostrar como configurar usando o Google Cloud Storage em um projeto fictício onde um notebook gera um arquivo .csv com dados numéricos aleatórios em 1000 linhas e 2 colunas com a seguinte estrutura:
├── .git/
├── .gitignore
├── .venv/
├── dados/
│ └── dados-aleatorios.csv
└── notebook/
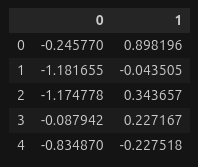
└── gera-dados.ipynbO primeiro arquivo .csv gerado tem as seguintes 5 primeiras linhas:
O primeiro passo é já ter inicializado o Git na pasta do seu projeto e vinculado ele ao seu repositório remoto. Depois, você deve inicializar o DVC no mesmo repositório navegando até a pasta dele pelo Terminal e usando o comando dvc init.
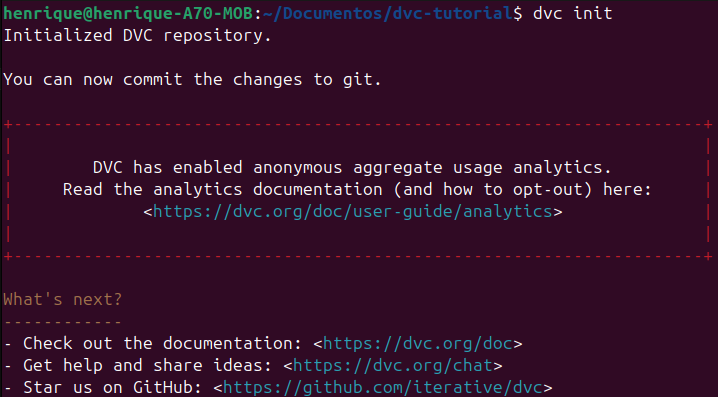
Após a execução do comando, são gerados os arquivos “.dvcignore” e “dvc/config” e o arquivo “.gitignore” é alterado para incluir alguns arquivos temporários do próprio DVC.
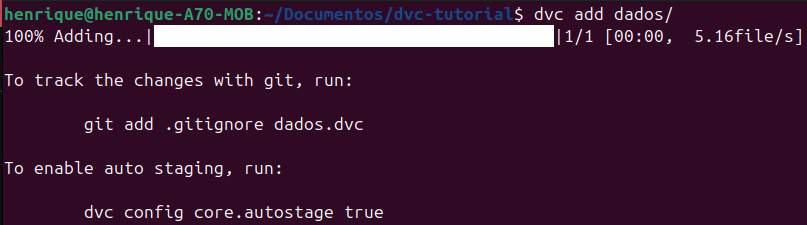
Após incluir esses arquivos no versionamento do Git e fazer o commit, você pode usar o comando dvc add dados/ para incluir a pasta com o arquivo .csv no versionamento do DVC.
Agora é a hora de escolher em qual bucket e pasta do Google Cloud os arquivos serão versionados. No meu caso eu criei a pasta “dvc-tutorial” dentro do bucket “dvc-files”. O comando para adicionar essa pasta como repositório remoto é o dvc remote add --default [nome do repositorio] gs://[nome do bucket]/[nome da pasta].

Para fazer o login na sua conta e autorizar o DVC a criar e excluir arquivos, deve ser executado o comando gcloud auth application-default login.
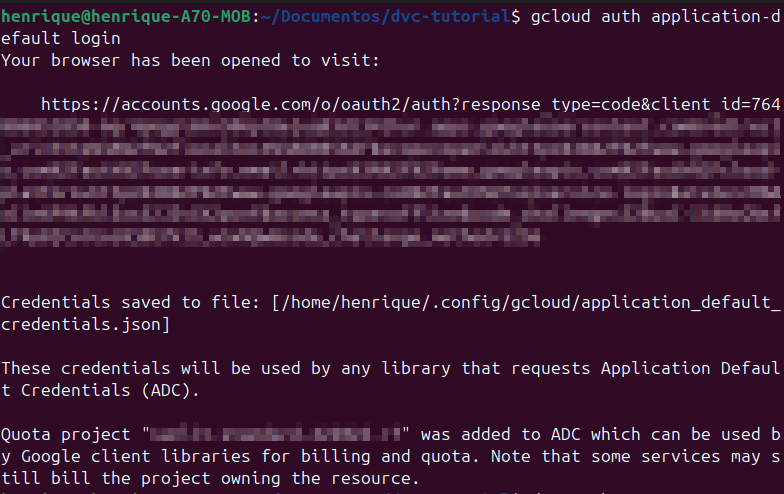
Após a execução do comando, é aberta uma aba no seu navegador onde é possível inserir o login e senha. Com isso, é salva uma chave de acesso no seu computador que permite que outros aplicativos interajam com os recursos do Google Cloud.
Agora, basta usar o comando dvc push para sincronizar a pasta dados e os arquivos dentro dela com o repositório remoto.

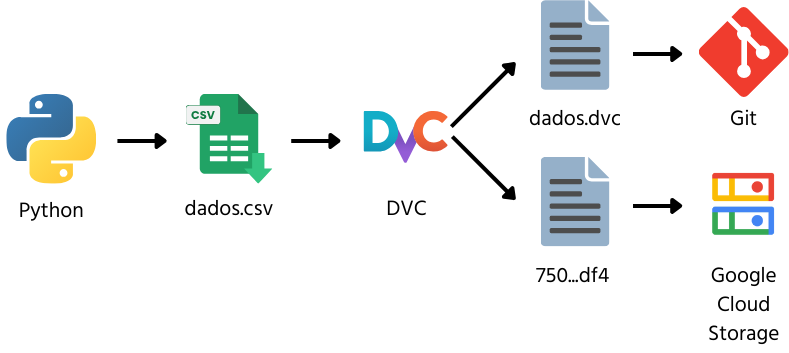
Um detalhe importante é que os dados que você versionar não são salvos no repositório remoto em seu formato e extensão originais. Executando o comando gsutil ls gs://[nome do bucket]/[nome da pasta]/** é possível ver que foram gerados dois arquivos para o meu csv:

O versionamento dos arquivos é feito agora pelo arquivo com extensão “.dvc” recém criado na sua pasta de projeto, no meu caso “dados.dvc”. Ele contém o hash MD5 do estado atual dos seus arquivos e deve ser incluído no GitHub juntamente com o arquivo “.gitignore” que foi alterado para não subir os dados da minha pasta “dados” diretamente no Git.
Agora vou gerar um novo DataFrame na mesma estrutura mas com outros dados aleatórios e substituir o meu arquivo .csv.
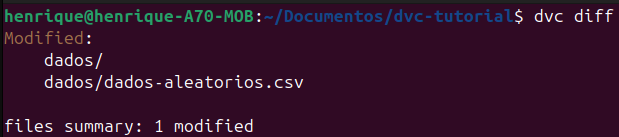
Feito isso, o comando dvc diff o DVC já identifica que tiveram mudanças na pasta dos dados.
O processo para salvar o estado atual dele é o mesmo para a primeira versão:
dvc add dados/para adicionar ele;dvc pushpara subir os arquivos para o bucket no Google Cloud;- Subir no GitHub o arquivo “dados.dvc”
Vamos supor agora que você tenha gerado dados de resposta de um modelo ou processo várias vezes e precise restaurar a versão de um arquivo que já foi substituído, como fazer isso?
O primeiro passo é saber qual é o hash do commit que você subiu o seu arquivo .dvc para o GItHub (aí está a importância de sempre ter commits bem comentados). Para listar os últimos 2 commits, você pode usar o comando git log -2 --format=oneline.

Agora você deve restaurar o arquivo “dados.dvc” que está na pasta raiz do projeto. Para isso, basta usar o comando git checkout 196adf – dados.dvc (aqui não é necessário usar o hash inteiro do commit, apenas os 6 primeiros caracteres já são suficientes).
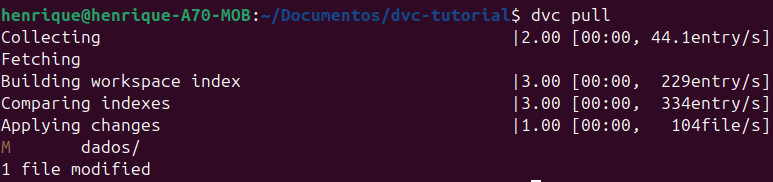
Com o arquivo “dados.dvc” fazendo referência à versão que você precisa, basta digitar dvc pull para baixar do Google Drive o arquivo .csv.
Por fim, vamos carregar novamente o arquivo .csv em um DataFrame do Pandas:
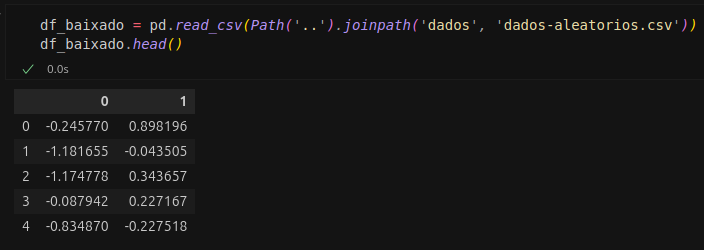
Aqui é possível ver que ele possui os mesmos dados da primeira versão gerada mesmo o arquivo tendo sido sobrescrito uma vez.
Depois de já ter todos os programas necessários instalados no seu sistema, o uso do DVC é relativamente fácil. Os comandos são semelhantes aos do Git e você tem a flexibilidade de versionar apenas os dados importantes para o seu projeto, trazendo a segurança de poder ter salvas as versões dos seus arquivos sem ter que colocar ao final do nome deles coisas como “_v1”, “_v2” e etc.
O fluxo para se usar o DVC pode ser resumido com os passos ilustrados na imagem a seguir:
Caso seja necessário, é possível consultar a documentação oficial também em DVC Documentation.
Deixe um comentário